ふりがな付きの文章の文字起こしが可能な日本語OCRアプリ「bunkoOCR for Mac/iPhone」がPDFからの画像取り込みや出力、トリミング処理などに対応しています。詳細は以下から。
![]()
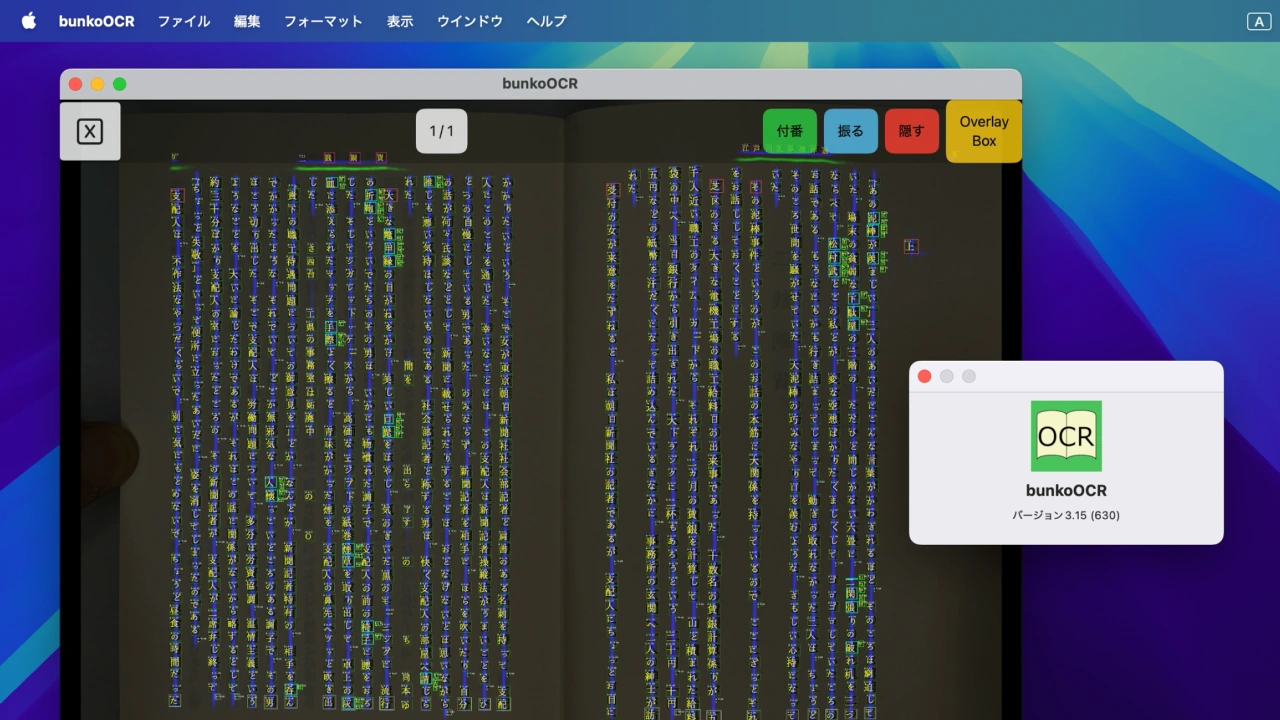
bunkoOCRは漢字の書き取りアプリなどを開発しているichiro NAKAHARAさんが2023年から開発しているMacやiPhone/iPad対応のOCRアプリで、縦書きと横書き、さらに文庫本など「ふりがな/ルビ」付きの日本語の文章を文字起こしすることができますが、このbunkoOCRがバージョン3.15アップデートでPDF内の画像の取り込みに対応しています。
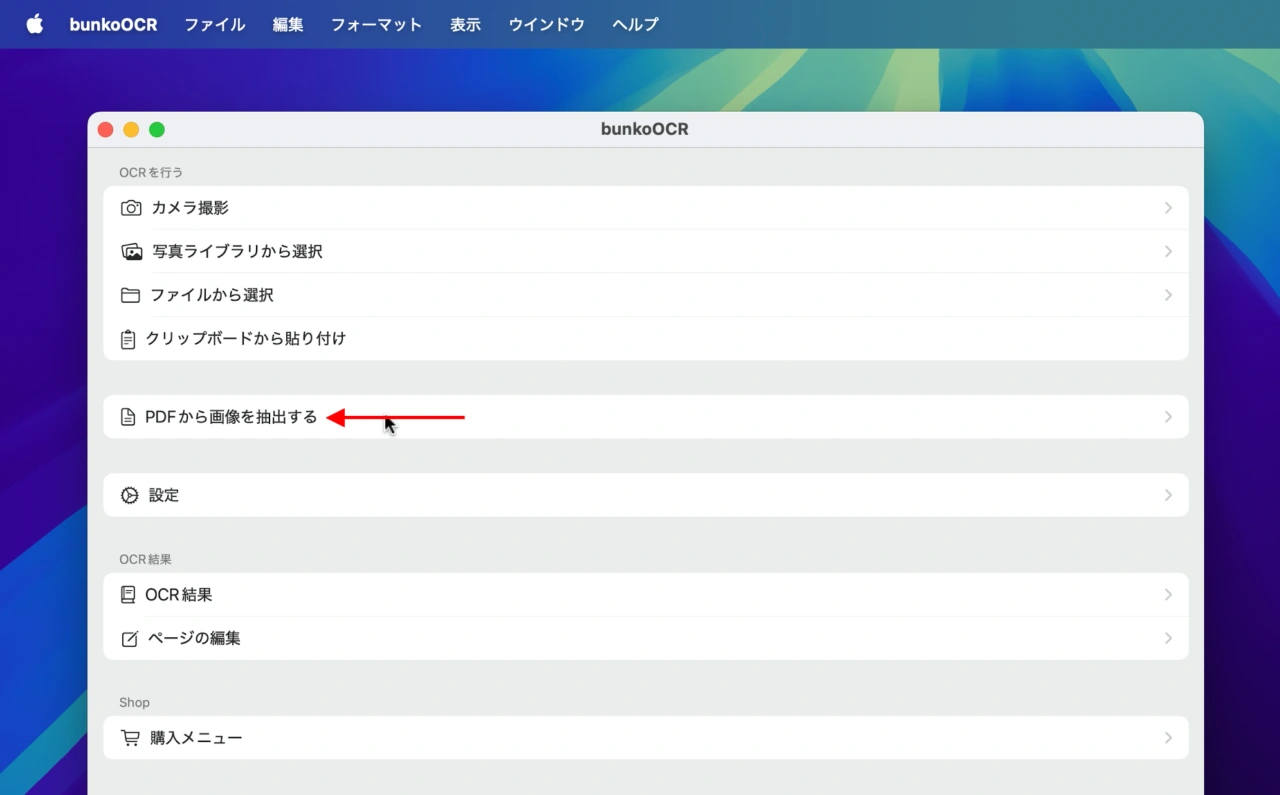
- pdfから画像のみを取り込むことができるようしました。
- OCR結果を、検索可能pdfファイルに出力できるようにしました。
リリースノートより抜粋
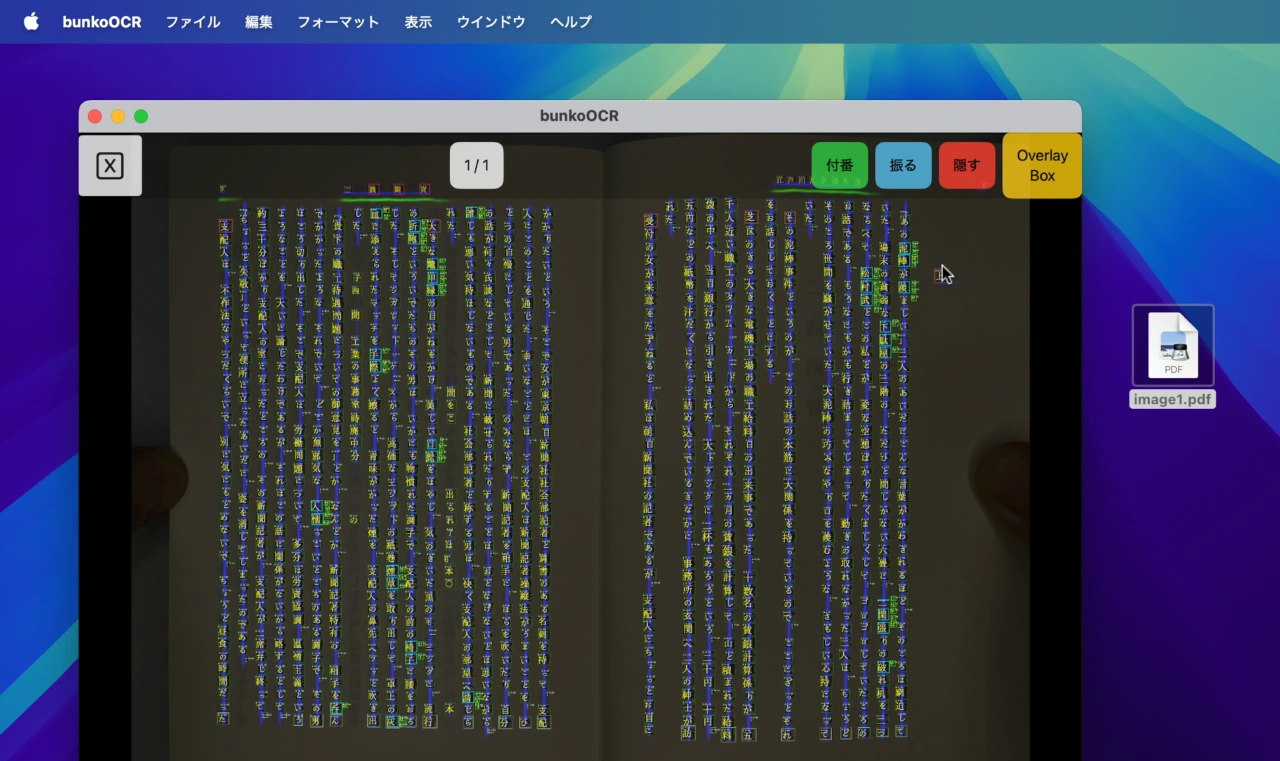
bunkoOCR v3.15では、新たに[PDFから画像を抽出]でPDFファイルを選択することで、PDFファイル内から画像のみを取り込みOCR処理できる他、OCR結果を検索可能なPDFファイルにして書き出すことが可能になっています。
また、同バージョンでは画像の上下左右のトリミング処理、画像全体が90度回転している場合に回転方向を指定して処理したり、自動での判定も可能になっています。
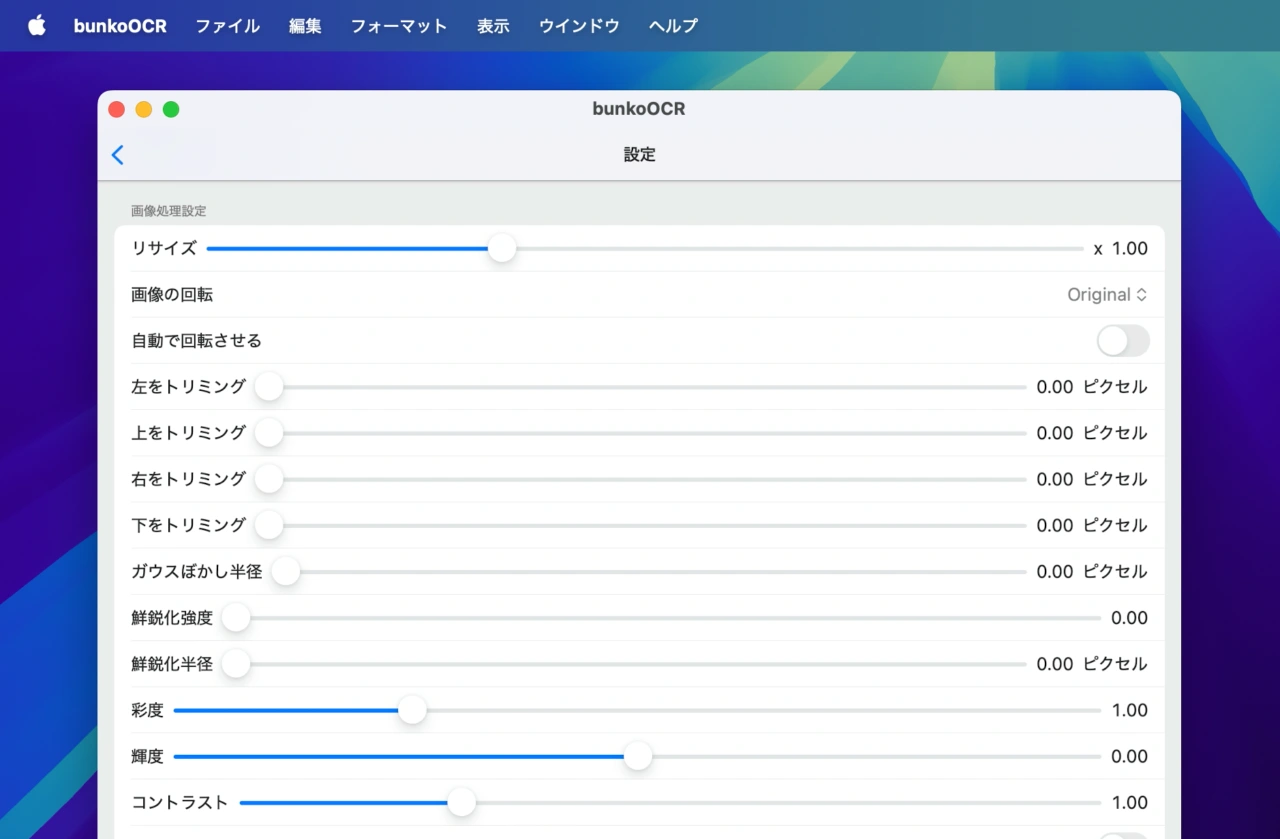
bunkoOCRの[設定]に追加された回転とトリミング
bunkoOCR v3.15のシステム要件はiOS/iPadOS 18のiPhone/iPad、macOS 15.0 Sequoia以降のMac、visionOS 2.0以降のVision Proで、アプリはApp Storeで無料公開されているので、日本語の縦書き&ルビ対応のOCRアプリををお探しの方は試してみてください。
bunkoOCR v3.15
- pdfから画像のみを取り込むことができるようしました。
- OCR結果を、検索可能pdfファイルに出力できるようにしました。
- 後段のTransformer処理のエラーを軽減するように処理を変更しました。
- 上下左右をトリミングして処理できるようにしました。
- 画像全体が90度回転している場合に、回転方向を指定して処理できるようにしました。自動で判定することもできます。
bunkoOCR v3.15 Demo
画像をスキャンしただけのpdfファイルに、OCR(光学文字認識)した透明テキストを埋め込んでテキストを検索可能にする方法です。
bunkoOCRアプリのver 3.15から、pdfファイルから画像を取り込んでOCR処理をして、元の画像のままpdfファイルにエクスポートする機能が追加されました。YouTubeより
- bunkoOCR – App Store
- bunkoOCR 3.15できました|lithium03 – note
コメント