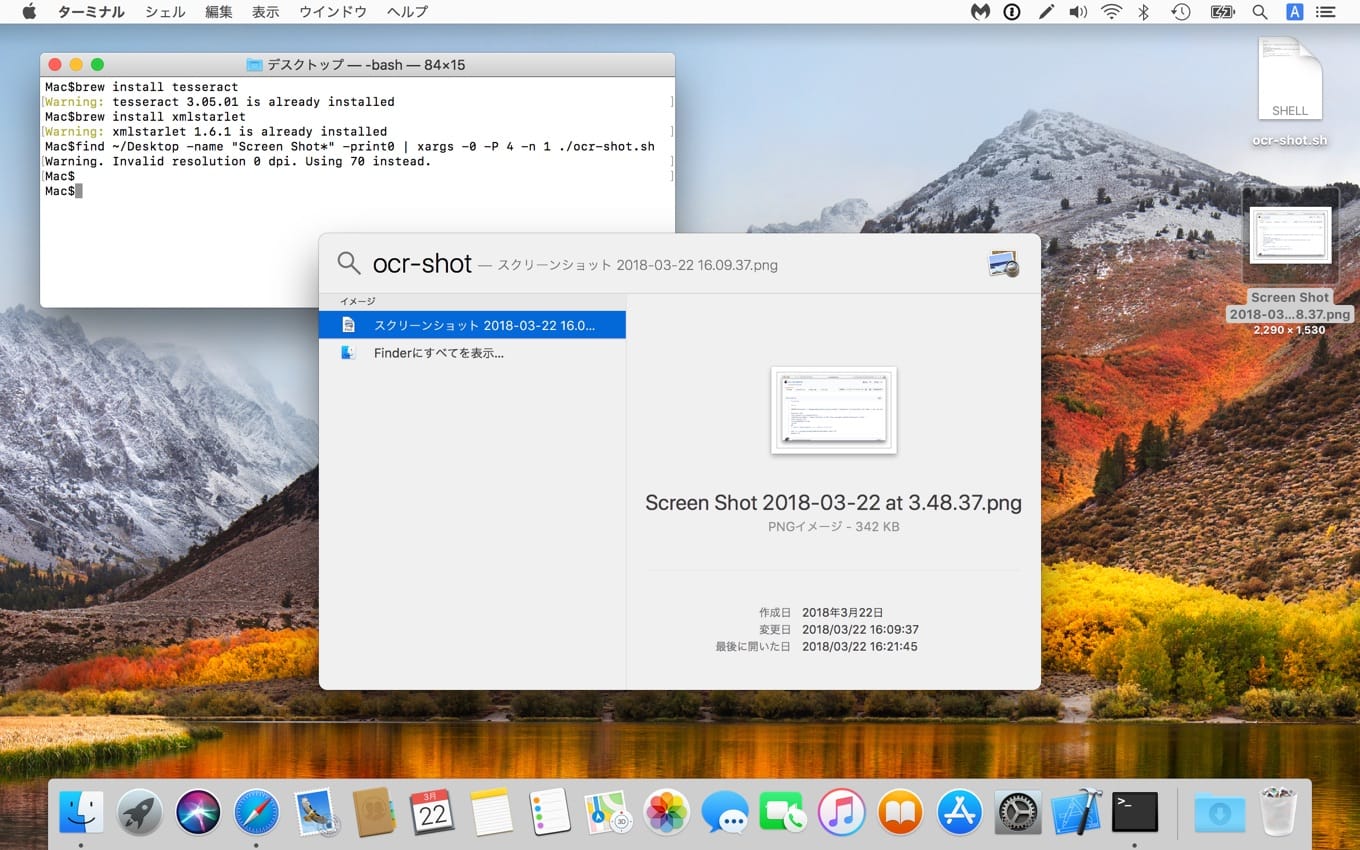
撮影したスクリーンショット画像をOCRにかけてmacOSのSpotlightで検索できるようにするスクリプト「ocr-shot」が公開されています。詳細は以下から。
![]()
macOSのSpotlight機能は検索用インデックスを作成し、ドキュメントに含まれている文章などを高速に検索することが可能ですが、撮影したスクリーンショット内にある文字列までは検索することが出来ません。そこで、この問題を解決するためのスクリプト「ocr-shot.sh」を米Eleos TechnologiesのエンジニアPhil Calvinさんが公開しています。
this is my new life's work. a script that OCRs screenshots and makes them searchable from spotlight. https://t.co/PdufbVLPOL pic.twitter.com/CHraxNcOog
— philip k dank (@pnc) 2018年3月17日
pnc commented
Probably needs brew install tesseract xmlstarlet.ocr-shot.sh – GitHub
ocr-shot.shの使い方
ocr-shotはオープンソースのOCRエンジン「tesseract」と「xmlstarlet」コマンドを利用し、撮影したスクリーンショットをOCRにかけてSpotlight用のxmlデータを作成するという手法を採用しており、使い方はまずbrewで両ライブラリをインストール。
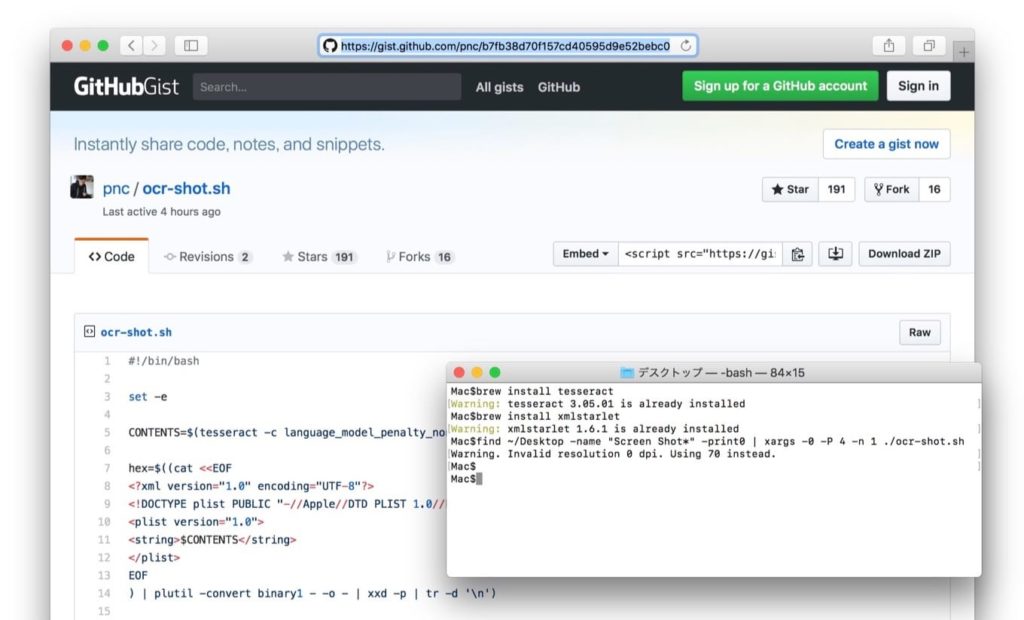
brew install tesseract xmlstarlet
次に、Gistから「ocr-shot.sh」をデスクトップに保存し、スクリーンショットを撮影します。”ocr-shot.sh”は英語環境でスクリーンショットを撮影した場合を想定しているので、撮影されたスクリーンショットはデスクトップに”Screen Shot*”という名前で保存されているものとして、以下の様に実行すると撮影したスクリーンショット内に含まれている文字列がSpotlight検索でヒットするようになります。
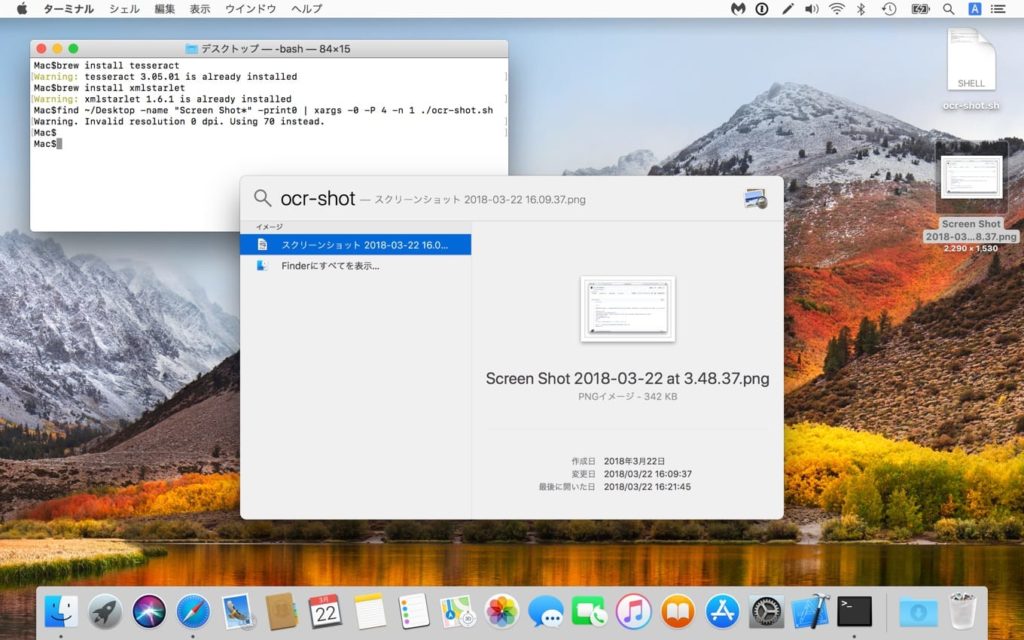
chmod a+x ocr-shot.sh find ~/Desktop -name "Screen Shot*" -print0 | xargs -0 -P 4 -n 1 ./ocr-shot.sh
処理するスクリーンショットの枚数が多いと多少時間もかかりますが、Calvinさんはocr-shot用のワークフローも公開してくれているので、興味のある方は試してみて下さい。
コメント
で、日本語対応なの?
Macはデスクトップのフォントの大きさを変えられないから、日本語識別に必要な1文字あたりの解像度を上げられない。
tesseract の起動オプションで言語を英語(-l eng)にセットしてますね。
日本語で使うなら、tesseract の開発版(4.0 beta)を使えば多少はマシになるでしょう。
あるいはGoogle のOCR APIを呼び出すか。
有償ソフトではなく、シェルスクリプトなんだから試してから記事にすべきでは。