iMac Proに搭載されるXeon Wプロセッサは「Intel AVX-512」をサポートするため、iMac Proはどう命令をサポートした初のMacとなりベクトル化されたコードはパフォーマンスが向上するそうです。詳細は以下から。
![]()
Appleは本日、iMacシリーズとして初めてXeon Wプロセッサを搭載した「iMac Pro」を発売しますが、今回の発売にあたりAppleはメディアやYouTuberの方々だけでなく、Cabel Sasserさんなど開発者の方にもレビュー用の「iMac Pro Intel Xeon 3.0GHz 10-Coreモデル」を送っており、
#Apple #iMac Pro “a true workstation class Mac” https://t.co/FB8UiKE4cv
— Philip Schiller (@pschiller) 2017年12月12日
The Xeon W also happens to be the first CPU in a Mac to support Intel’s AVX-512 vector processing, which increases the width of vector registers to 512 bits (up from 256 bits in AVX2) and doubles the number of vector registers to 32 per core (up from 16 in AVX2). I’ll talk more about that in a bit.
2017 iMac Pro Review – Craig Hunter
その1人に選ばれた航空宇宙工学のエンジニアで、Hunter Research & Technologyを設立しARを利用したiOSデバイス用アプリを開発しているソフトウェア開発者のCraig Hunterさんが自身の専門分野からiMac Proのレビューを投稿しています。
CFD
Hunterさんによると、iMac ProはNACAエアフローの様な数値流体力学(CFD)の分野において自身が過去5年間利用してきたMacやLinuxサーバーの中で最も優ていたそうで、
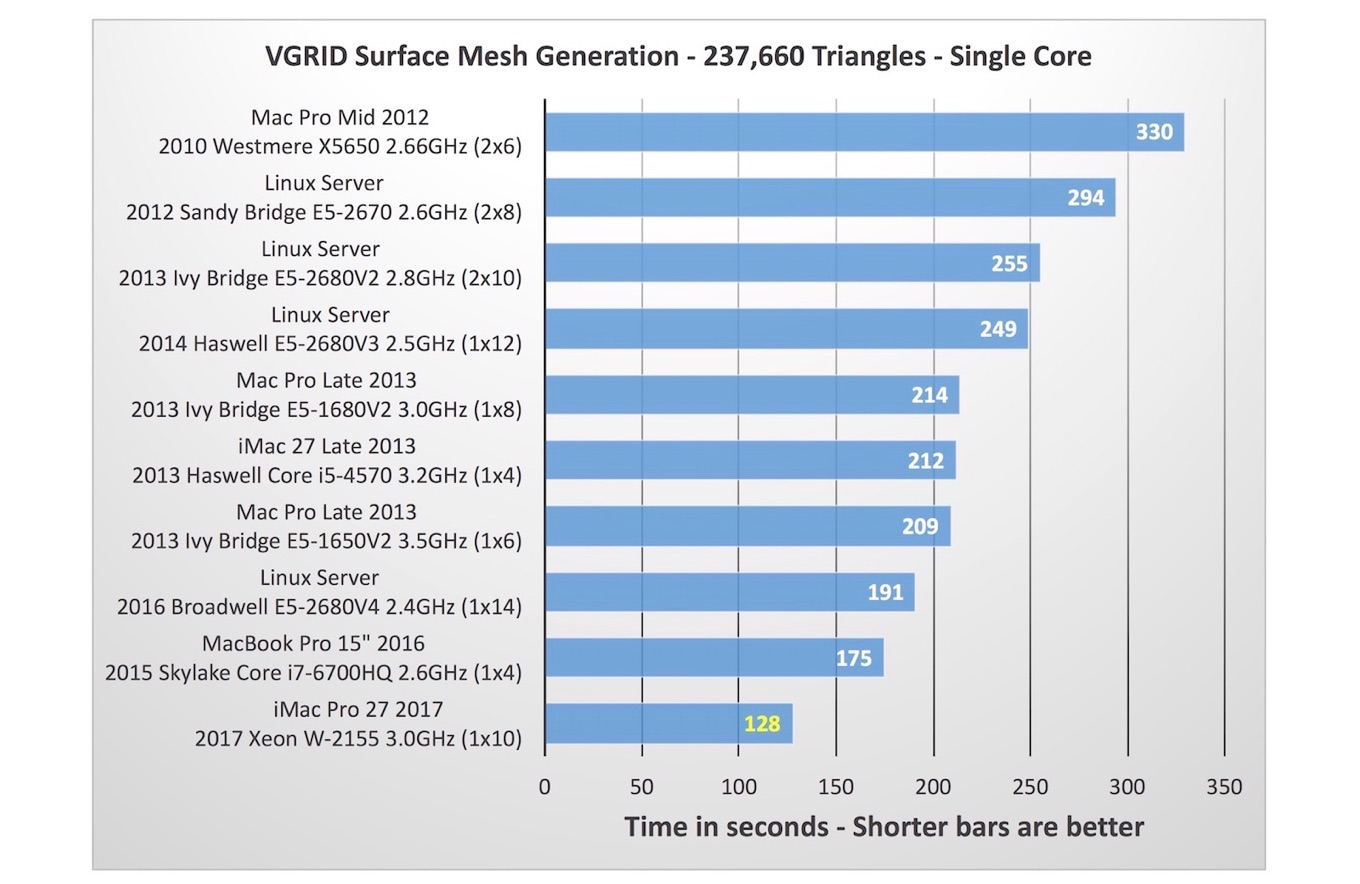
237,660のトライアングルメッシュを作成するのにかかった時間[s]
NACA 0012エアフローの様に並列処理が可能な流体シミュレーションでは3.0GHz 10-Coreを利用した並列計算のパフォーマンスもMacBook Pro 15-inch Skylake Core i7-6700HQ 2.4GHz 4-CoreやMac Pro Late 2013 Ivy Bidge E5-1650 v2 3.5GHz 6-Core以上の性能となったそうです。
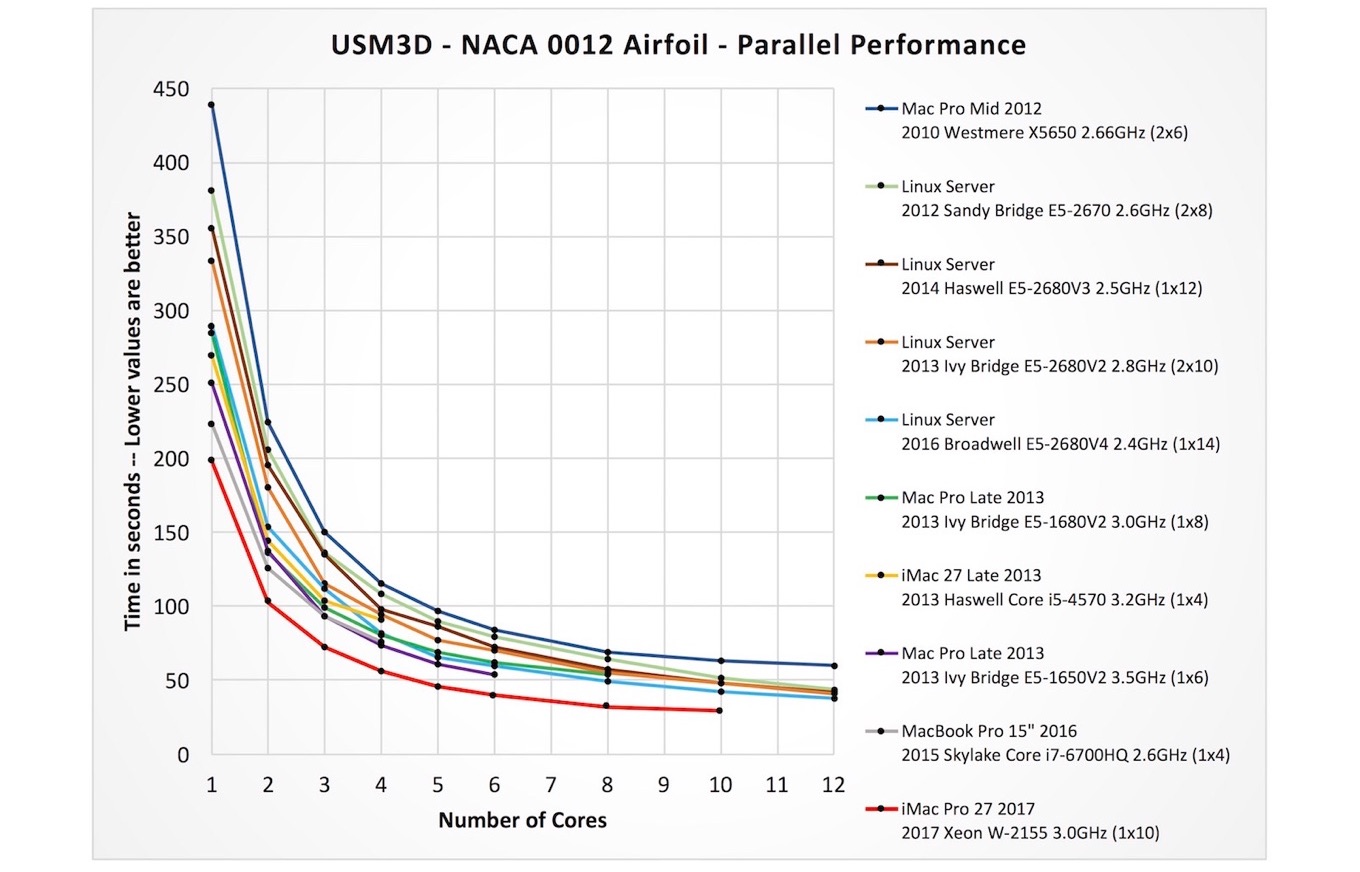
Here, we compute flow around a NACA 0012 airfoil. Results are plotted to show the computation time (in seconds) as a function of the number of cores used, ranging from 1,2,3,4…. up to 12 cores on some machines. Among the same set of computers compared above, the iMac Pro (red curve on the bottom) again fares very well, coming in with notably lower times all the way up to 10 cores:
2017 iMac Pro Review – Craig Hunter
AVX-512
また、iMac Proに搭載されているIntel Xeon W-2155(正確にはXeon W-2150B[1, 2])はIntel AVX-512 SIMDを利用したベクトル演算を行うことが可能で、コードの詳細には触れていませんがHunterさんは配列をベクトル化した演算を単精度(32-bit)と倍精度(64-bit)で行い、その計算速度比を出しており
for (i=0;i<N;i=i+8) {
__m512d a_vec = _mm512_load_pd(&a[i]);
__m512d b_vec = _mm512_load_pd(&b[i]);
__m512d c_vec = _mm512_add_pd(a_vec,b_vec);
_mm512_store_pd(&c[i],c_vec);
}
その結果によると、AVX-512を利用した倍精度計算では基準となる計算の5.2倍、単精度では10.1倍計算速度が向上したそうで、Intel AVX2と比較しても60~70%程向上していることが確認できたそうです。
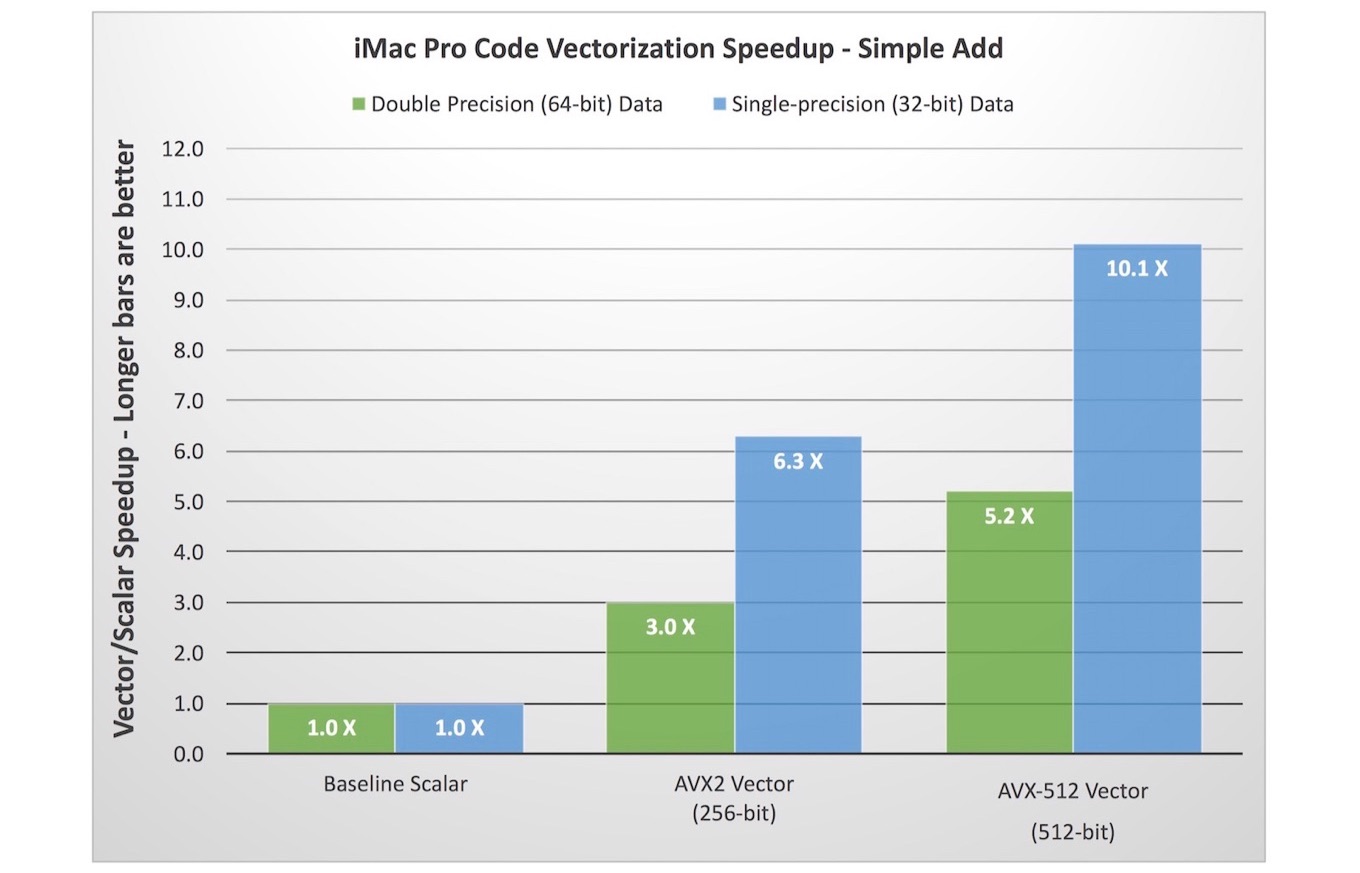
You’d be right to expect an 8X increase in performance here, but in reality that’s a bit theoretical and in the real world it’s going to be less. How much less depends on a lot of things, like the data size, whether it fits in the various caches or spills onto RAM, and so on. But in this case, picking N=512, the results are pretty good, with a 5.2X speedup from AVX-512. For comparison, I also included AVX2 results, using 256-bit wide vectors that can hold 4 doubles at a time. This nets a 3.0X speedup. And though I won’t get into the coding details here, running the same tests using single-precision floats nets speedups of 10.1X for AVX-512 and 6.3X for AVX2.
2017 iMac Pro Review – Craig Hunter
AVX-512への最適化については最近のコンパイラは最適化オプション(-O2や-O3)付けることで自動的に行なってくれるそうで、IntelのMKLはもちろん、AppleのAccelerateフレームワークもAVX-512を利用するようになっているようで、Hunterさんはこの他にも並列化のスケーリングやXcodeによる自身のアプリのコンパイル時間についても触れているので、興味のある方はHunterさんのブログをチェックしてみて下さい。
Most of my apps have around 20,000-30,000 lines of code spread out over 80-120 source files (mostly Obj-C and C with a teeny amount of Swift mixed in). There are so many variables that go into compile performance that it’s hard to come up with a benchmark that is universally relevant, so I’ll simply note that I saw reductions in compile time of between 30-60% while working on apps when I compared the iMac Pro to my 2016 MacBook Pro and 2013 iMac.
2017 iMac Pro Review – Craig Hunter
- 2017 iMac Pro Review – Craig Hunter
- インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) の概要 – Intel

コメント
悪いんだけど、intelは本当の高速化はしないんだよね。株主の顔を伺ってるから。
元インテルジャパンの人曰く、ベンチマークテストをハードコーディングしたとしたら、それはCPUが早いとは言えない。同様に、便利な命令を搭載したからインテルのCPUは早いのではない、と株主にアピールしてるわけ。
倍精度浮動小数点演算を4つ実行するのは素晴らしいが、命令が長過ぎてショートブランチが使えないし、汎用レジスタが少な過ぎるのでしばしばパイプラインが崩れてペナルティを食らう。
結局86アーキテクチャは平屋を高層ビルに仕立ててるだけ。